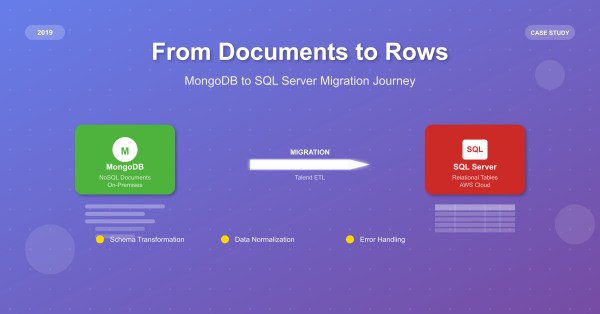
Twenty years ago, I had zero programming experience. Today, I'm a data architect who watched countless technologies rise and fall while SQL remained unshakeable. From converting COBOL programs to solving critical performance crises, SQL became my career passport through developer, analyst, engineer, and architect role
Twenty Years with SQL: The Language That Never Goes Out of Style