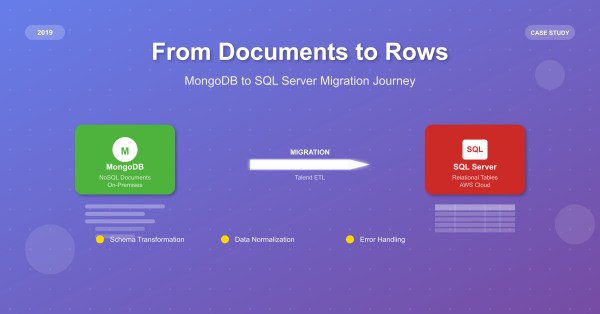
When I received a MongoDB to SQL Server migration requirement in 2019, I had to pause. This wasn't typical relational-to-relational migration—it meant transforming flexible documents into rigid, normalized tables. Here's how I bridged two completely different data paradigms using Talend and what I learned about heterogeneous database migrations.
From Documents to Rows: Our Journey Migrating MongoDB to SQL Server in AWS